大语言模型推理加速器中的进阶数制格式
Anda: Unlocking Efficient LLM Inference with a Variable-Length Grouped Activation Data Format
基本信息
- 时间:2025年,HPCA
- 作者:Chao Fang,Man Shi(通讯),Robin Geens, Arne Symons, Zhongfeng Wang(通讯),Marian Verhelst
- 单位:南京大学和比利时鲁汶大学
背景
广泛使用的大型语言模型仅对权重进行量化,利用INT-权重并保留FP-激活,这样在减少存储需求的同时保持了准确性。然而,这导致了能量和延迟瓶颈向与昂贵的内存访问和计算相关的FP激活转移。现有的LLM加速器主要专注于计算优化,忽视了在LLM推理中占主导地位的FP-INT GeMM操作上联合优化FP计算和数据移动的潜力。
基本内容
作者提出了anda数制格式:一种创新的可变长度尾数BFP方案,专为高效的大型语言模型推理而设计。安达的结构包括一个符号位、一个共享指数和一个可变长度尾数,建立在传统BFP转换过程之上。其关键特性是能够根据不同张量的精度敏感性动态选择尾数长度,保持每个张量内的一致性,同时优化准确性与效率的权衡。
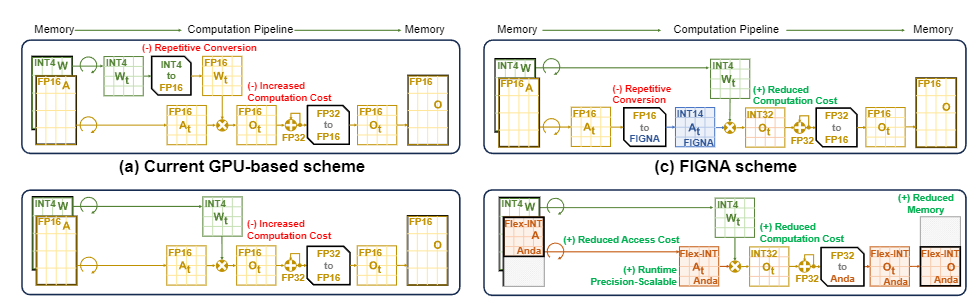
配备专用FP-INT处理单元的GPU平台可以消除将INT4权重转换为FP16的需要,从而减少了数据转换开销和计算成本。FIGNA提出了一种使用相应硬件支持的BFP变体的计算方案,以克服专用FPINT单元的问题。激活在内存中以FP16格式存储,在计算前转换为FIGNA格式,然后使用14位尾数与INT4权重相乘进行GeMM计算。最终结果再次转换为FP16并写回内存。然而,由于在计算过程中需要频繁访问FP16激活,从FP16到FIGNA的频繁数据转换引入了额外的开销,影响了整体效率。
作者提出的Anda格式计算方案与先前的方法相比具有一些独特的优势:
- 激活不再以FP16格式存储在内存中,直接以Anda数据格式存储,减少了存储开销和数据访问开销,同时避免了频繁的数据转换。
- 共享指数使得可以在组内进行INT点积操作,然后跨组进行FP32累加,减少了FP-INT GeMM的计算开销。
- 可变长度尾数显著减少了点积操作和内存访问所需的字长最小化。
- 仅在将最终的FP32结果写回内存之前将其转换回Anda格式,最小化了存储需求以及切换数据格式带来的额外开销。
自适应精度搜索算法
自适应精度搜索算法是作者提出用于在仅权重量化的语言模型中进行激活精度优化的离线编译时算法:
- 确定搜索空间:算法将搜索空间缩小到四种关键张量类型($A_{qkv}, A_o, A_u, A_d$)的精度,这些类型基于它们对模型准确性的敏感性。
- 快速评估和优先级排序:使用一种无需训练的一次性校准过程,算法快速评估不同的精度组合,并使用位操作作为指标来估计计算成本,从而优先考虑有希望的组合。
- 更新和放宽最佳组合:如果某个组合在保持准确性的同时具有更低的BOPs,它将成为新的最佳组合。算法然后通过减少最佳组合中每个张量类型的尾数长度来生成附近的精度候选,并将未访问过的候选添加到优先队列中。
- 迭代和终止:算法重复步骤2和步骤3,直到达到最大迭代次数或搜索空间被耗尽。如果生成的候选组合不满足准确性约束,则不进行更新。
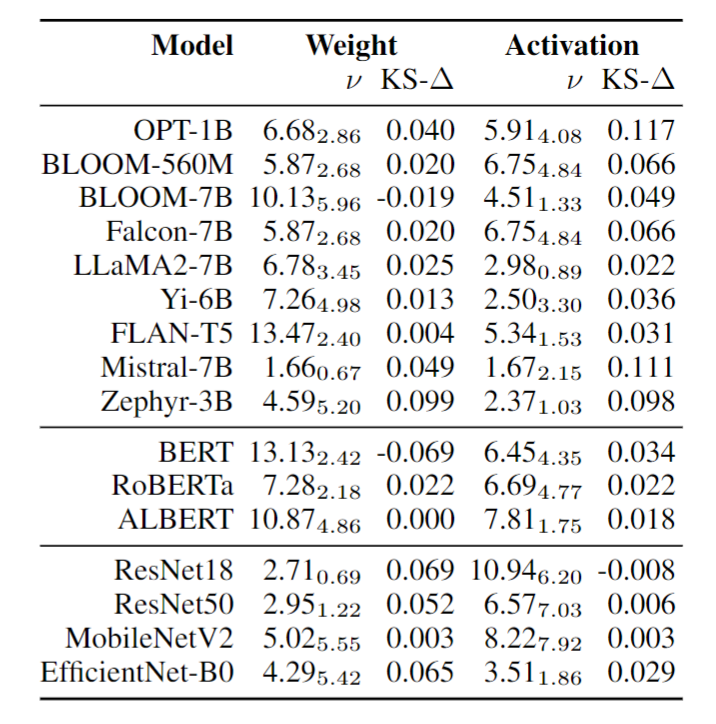
测试结果
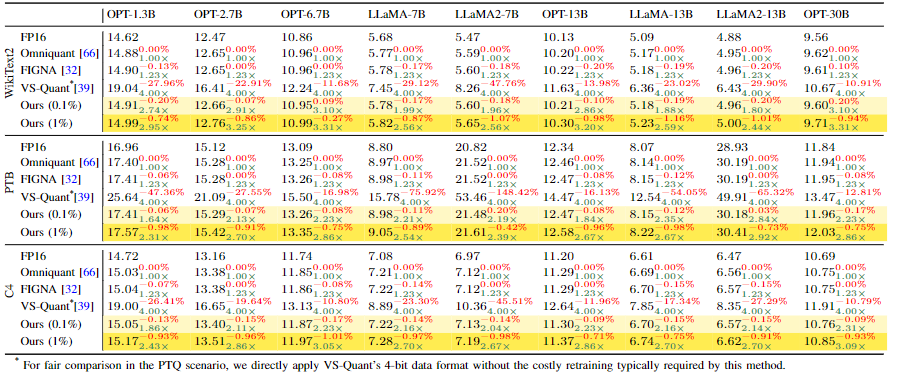
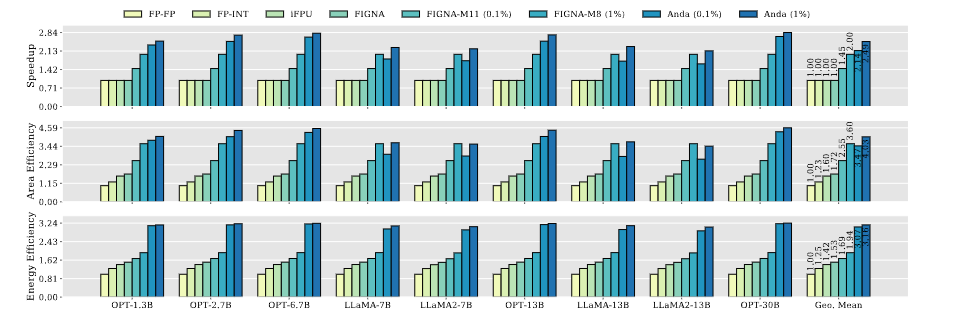
AMXFP4: Taming Activation Outliers With Asymmetric Microscaling Floating-Point For 4-Bit LLM Inference
基本信息
- 时间:2024年11月,arxiv
- 作者:Janghwan Lee,Jiwoong Park,Jinseok Park,Yongjik Kim,Jungju Oh,Jinwook Oh,Jungwook Choi
- 单位:汉阳大学
背景与挑战
MXFP4对于LLM推理的稳健性仍然未被充分探索:作者对LLaMA2的评估发现,与MXFP8相比,在MMLU基准测试上的性能显著下降,说明对于稳健的4位推理,需要数据格式创新。
基本内容
作者提出了非对称微缩4比特浮点(AMXFP4)以实现高效的LLM推理,利用非对称共享比例来减轻异常值的影响。
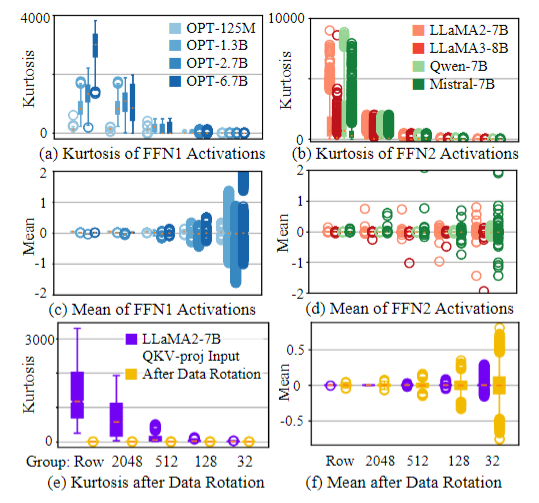
随着组大小的减小,llama和opt两种模型类型中的异常值主导地位都减少。在GS = 32时,峰度几乎消失,这表明组内的激活动态范围更适合量化。这一观察有助于解释MXFP8在选定LLMs的直接转换中的初步成功,但它并不能解释MXFP4的失望表现。而组均值的箱线图,反映了分布的不对称性。在大组大小的情况下,组均值围绕零中心,但随着组大小的减小,均值显著分散。这种分散表明,MX格式中通常使用的对称数据表示对于微缩激活量化来说不是最优的。
提出的数据格式
非对称浮点量化:在浮点量化中,非对称性应用于刻度,这是因为浮点数固有的以零为中心的表示。一个指数位移的尾数表示一个值,然后根据符号乘以正或负的共享刻度。作者定义非对称浮点量化如下:
$$x_q=\left{\begin{array}{l}(-1)^s \cdot 2^{E+e b} \cdot M \cdot\left(2^{s e b_p} \cdot \hat{M}_p\right) \text { if } s=0, \ (-1)^s \cdot 2^{E+e b} \cdot M \cdot\left(2^{s e b_n} \cdot \hat{M}_n\right) \text { if } s=1,\end{array}\right.$$
其中$s$、$E$、$eb$和$M$分别代表元素的符号、指数、指数偏移和尾数。$2^{s e b_p} \cdot \hat{M}_p$ 和 $2^{s e b_n} \cdot \hat{M}_n$表示在量化组内共享的正负刻度。
根据均值和峰度的相似性对组进行聚类,然后进行Lloyd-Max算法以接近理想的量化数字表示(100次迭代;组的数量设置为16,因为更多的组没有观察到MSE的进一步减少)
共享比例选择:使用5位指数,E5M2有效地缓解了由于动态范围有限而导致的精度损失。
测试结果

如表所示,作者研究了QuaRot和SpinQuant对不同校准集分布的敏感性。测量了在校准和评估数据集相同以及不同的情况下的困惑度PubMed和Enron邮件。QuaRot和SpinQuant性能有显著提升,有一个例外是,当使用PIQA数据用于校准时,SpinQuant在PIQA和WinoGrande上都取得了高性能,尽管仅因校准数据集的变化就出现了2-3%的性能差异,这表明基于校准的方法对数据集非常敏感。MXFP4-PoT不受校准集的影响,但表现出严重的性能退化,而提出的AMXFP4-FP8显著提升了性能,超过了传统的基于校准的方法。
MicroScopiQ: Accelerating Foundational Models through Outlier-Aware Microscaling Quantization
基本信息
- 时间:2024年11月,arxiv
- 作者:Akshat Ramachandran、Souvik Kundu、Tushar Krishna
- 单位:乔治亚理工学院、Intel
主要内容
MicroScopiQ在保留更高精度异常值的同时,剪枝一定比例的重要性最低的权重,以分配额外的异常值位。使用MX-FP对异常值进行更高精度的量化,而使用MX-INT对内值进行量化。与OliVe不同的地方,MicroScopiQ不简单地修剪相邻的值,而是利用Hessian信息来识别最不重要的值进行修剪。
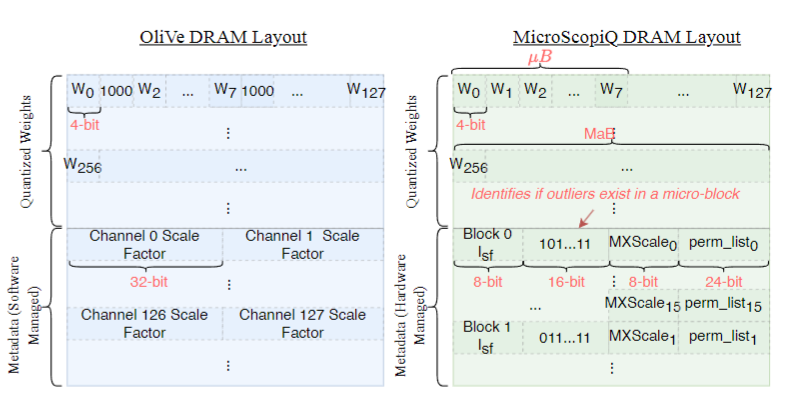
待量化的每一行被划分为多个大小为128的非重叠连续宏块(B)。一个MaB内的所有内值都共享相同的比例因子进行量化。然后,每个MaB再细分为多个大小为𝐵𝜇 = 8的非重叠连续微块𝜇Bs,十六个𝜇Bs组成一个MaB。每个𝜇B中的异常值共享相同的比例因子。每个MaB中识别内值和异常值。计算一个共享的8位2的幂次比例因子,根据在识别出𝜇B中的异常值,计算一个共享的8位MXScale,通过连接一级2的幂次比例因子和二级微指数来计算。
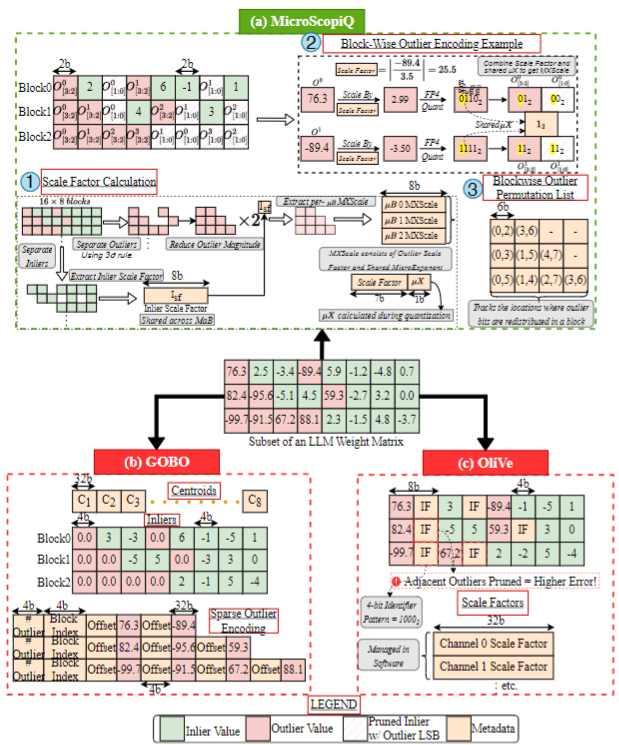
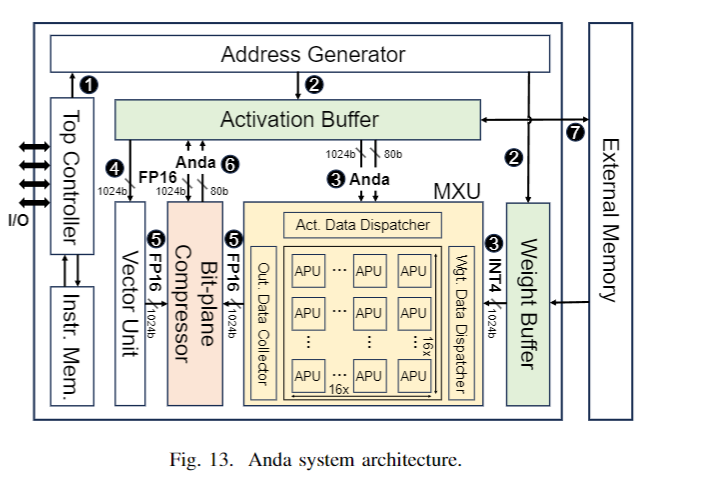
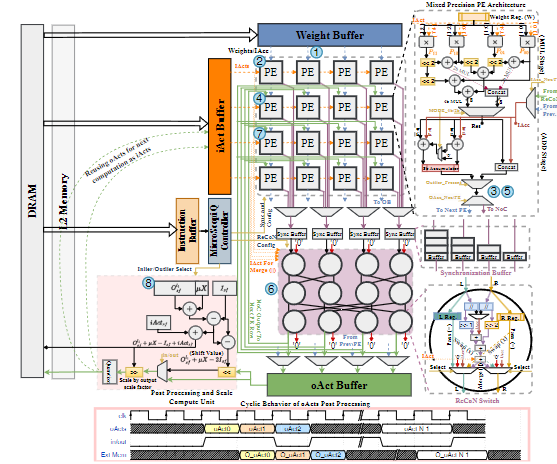
再对算法做对应的硬件结构:
测试结果
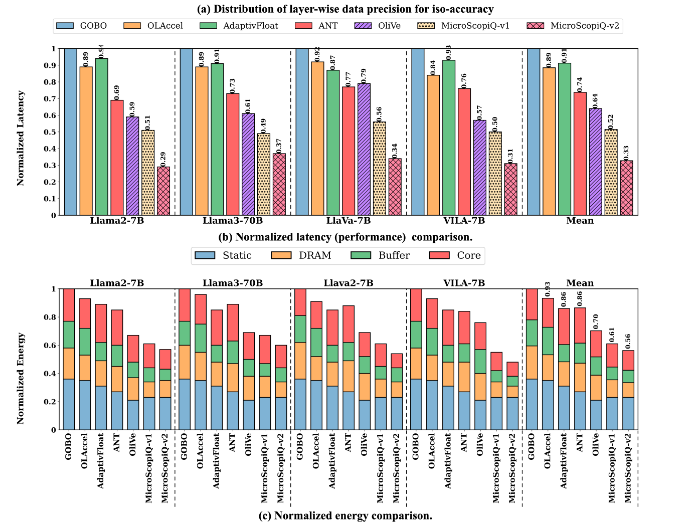
MicroScopiQ v1和v2在所有模型上始终优于所有基线,分别实现了1.50倍和2.47倍的平均加速,能耗和延迟效果与其他相比最好。
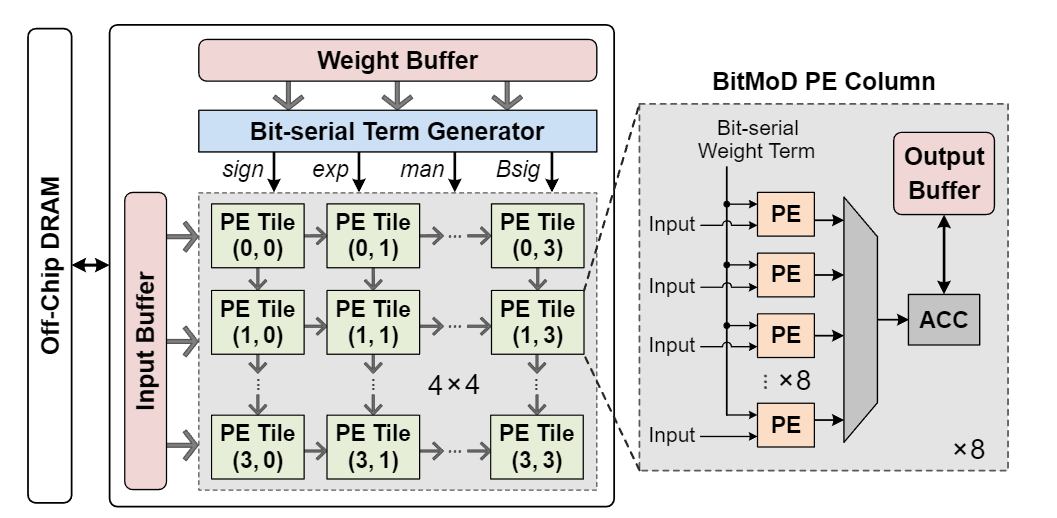
BitMoD: Bit-serial Mixture-of-Datatype LLM Acceleration
基本信息
- 时间:HPCA,2025
- 作者:Yuzong Chen, Ahmed F. AbouElhamayed,Xilai Dai, Yang Wang, Marta Andronics, George A. Constantinules, Mohamed S. Abdelfattah
- 开源代码:https://github.com/yc2367/BitMoD-HPCA-25
- 单位:康奈尔大学、微软、帝国理工学院
背景
GPU缺乏专用的硬件来执行整数权重与浮点激活之间的乘法
内容
数制格式
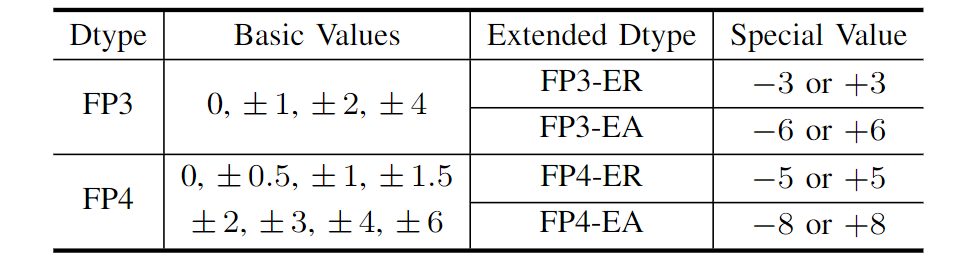
作者认为可以通过将fp种一个多余的零值重新定义为另一个特殊值来为FP引入额外的非对称性。这种方法提供了两个关键好处。首先,它允许我们充分利用有限的量化级别。尽管多余的零值不影响高精度格式,如FP16,但它构成了低精度量化级别的一大部分。其次,可以调整特殊值,使扩展的FP数据类型更好地适应逐组权重分布。
按组量化必须在计算每组点积后对部分和进行去量化,因为不同的组有不同的缩放因子。此外,由于BitMoD保持输入激活为FP16,组部分和也将具有浮点格式。作者在前人工作VS-Quant的基础上进行了改进,VS-Quant应用了第二级量化,将缩放因子进一步量化为低精度整数。给定权重通道大小D和组大小G,VS-Quant对同一通道的D/G个缩放因子应用对称量化,其中每组缩放因子的精度是一个设计参数。因此,我们进行了实验以找到每组缩放因子的最佳精度。在BitMoD中使用INT8每组缩放因子,这使得在硬件中可以以位串行方式中高效地进行每组去量化。
统一表示来处理不同的权重数据类型
硬件方面的设计目标是支持各种数制INT8、INT6以及在统一架构中的新的FP4和FP3扩展。作者出了一种统一的位串行表示,其中每个数字都被分解为一系列位串行项,每个项包含四个部分:符号、指数、尾数和位重要性。位串行项的值可以表示为:
$$v_{\text {term }}=(-1)^{\text {sign }} \cdot 2^{\text {exp }} \cdot \operatorname{man} \cdot 2^{\text {bsig }}$$
Ascend HiFloat8 Format for Deep Learning
基本信息
- 时间:arxiv,24年9月
- 作者:人有点多,Yuanyong Luo是通讯
- 单位:华为
内容
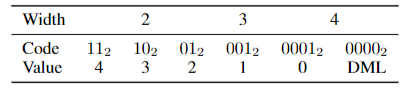
论文提出了一个数据格式HiFloat8,就是基于fp9然后可变的尾数、指数长度,相比fp8加了一个dot位,这个位长度从2到4位。
- dot位为2位时,11、10、01表示指数位的长度是4、3、2,对应的尾数位的长度是1、2、3
- dot位为3位时,001表示指数位的长度是1,对应的尾数位的长度是4
- dot位为4位时,0001表示指数位的长度是0,对应的尾数位的长度是5,0000代表的是非规约数

这是规约数的计算公式:
$$X = (-1)^S \times 2^E \times 1.M$$
这是非规约数的计算公式:
$$X = (-1)^S \times 2^{M-23} \times 1.0$$

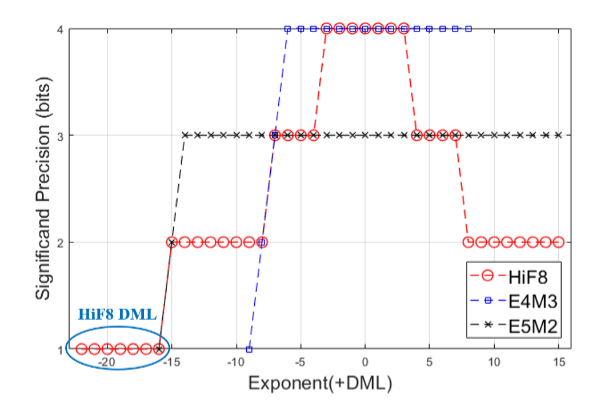
HiF8、FP8和FP16格式的典型编码值和特性。对于二进制模式下的HiF8格式,黑色位是符号域,红色位是点域,绿色位是指数域,蓝色位是尾数域。HiF8支持所有特殊值,但不区分正零和负零。
实验结果
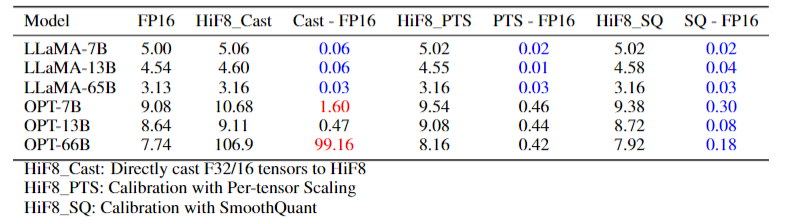
通过HiF8训练的LLM可以直接用于推理,论文还进一步评估了SmoothQuant校准方法用于LLMs。首先,对量化相对不敏感的LLaMA和对量化敏感的OPT作为实验用的LLMs。对于一些对量化不敏感的大语言模型,如LLaMA,即使只进行最简单的直接转换,HiF8也能达到期望的推理精度。但对于一些对量化敏感的大语言模型,如OPT,则需要专门的校准方法,如PTS(逐张量缩放)和SmoothQuant,来提高HiF8的推理精度。
QLoRA: Efficient Finetuning of Quantized LLMs
基本信息
- 时间:NIPS’23
- 作者:Tim Dettmers、Artidoro Pagnoni、Ari Holtzman、Luke Zettlemoyer
- 单位:华盛顿大学
内容
NF4的数据格式
神经网络权值通常具有标准差为0的正态分布性质,分位数量化技术的主要思想是将数值尽量落到均值为0,标准差为[-1,1]的正态分布的固定期望值上:
- 首先先将数据归一化,除以数据里的最大值。
- 把正态分布曲线分为16个部分(概率相等),每个部分用左右值之和的二分之一来代表这一部分,然后给数据里找接近的作为索引
比如[1.672,0.987,-1.1]
先归一化为[1.0, 0.590, -0.658],这个对应的scale=1.672
再根据划分的部分查表得到index,[15,13,1]
双重量化
对量化常数进行二次量化,以进一步减少内存占用
分页优化器
使用NVIDIA的统一内存特性,当GPU内存不足时,自动将部分数据转移到CPU内存中,以管理内存峰值。
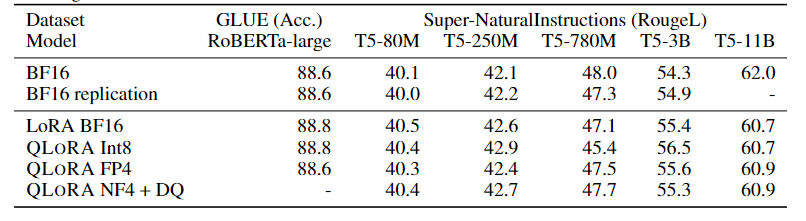
结果
实验的结果一致表明,4位QLoRA使用NF4数据类型在具有良好评估设置的学术基准上,能够匹配16位全模型微调和16位LoRA微调的性能。实验还展示了NF4比FP4更有效,双重量化不会降低性能。
并且,QLORA将65B参数模型的微调平均内存需求从超过780GB的GPU内存降低到小于48GB,同时在与16位全微调基线相比的情况下,运行时间或预测性能没有下降。
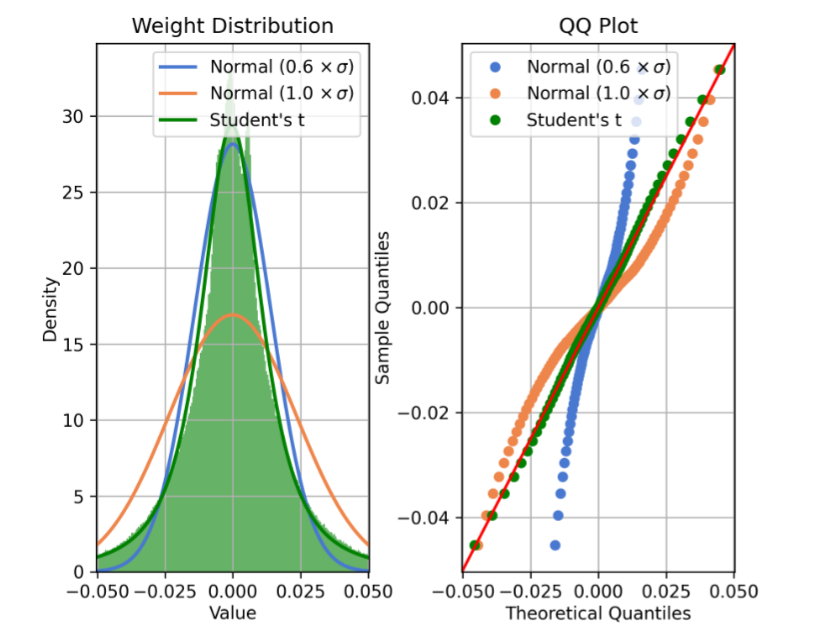
Learning from Students: Applying t-Distributions to Explore Accurate and Efficient Formats for LLMs
基本信息
- 时间:arxiv,24年5月发的,被ICML2024接收
- 作者:Jordan Dotzel(通讯)、Yuzong Chen、Bahaa Kotb、Sushma Prasad、Gang Wu、Sheng Li、Mengwei Ding、Zhiru Zhang
- 单位:康奈尔大学、谷歌
内容
把上面那个正态分布换成t分布