大语言模型推理加速器中的数制格式与基础架构
背景与挑战
论文中的浮点输入或许不是最好的数制(Data Format),为了提高硬件效率,可以选择更好的数制。主要参考了两篇数制格式规范:
- 《Microscaling Data Formats for Deep Learning》
- 《OCP Microscaling Formats (MX) Specification》
FIGNA: Integer Unit-based Accelerator Design for FP-INT GEMM Preserving Numerical Accuracy
基本信息
- 时间:2024,HPCA
- 作者:Jaeyong Jang, Yulhwa Kim, Juheun Lee, Jae-Joon Kim
- 单位:Seoul National University
背景挑战
仅权重量化通过使用int-权重来减轻大型语言模型的计算负担,同时保留fp-激活以确保推理质量。尽管通过减少权重参数的位精度实现了内存占用降低,但由于缺乏专用的FP-INT算术单元,实际的计算性能往往没有显著提升。
基本内容
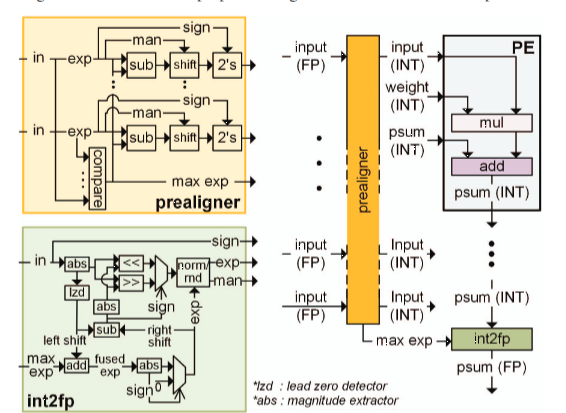
先是预对齐器将FP值转换为INT值,预对齐器识别FP激活矩阵中向量的最大指数。然后,根据每个FP激活自己的指数与最大指数之间的差异来调整尾数,共享一个公共的最大指数来指示激活向量的尺度。再可以用INT-INT MAC操作替换FP-INT MAC操作,在完成与权重矩阵的整个内积之后,int2fp单元再转换回FP格式。
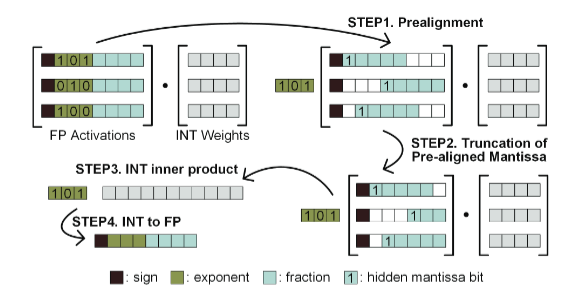
为了保持数值精度,同时减少乘法器的大小,作者提出可以在计算前截断预对齐尾数的较少重要位。根据作者文中的讨论,当权重中包含0值时,乘法后的比例变化变得不可预测,作者提出了一个无0的带符号INT格式,这种格式可以避免在计算时遇到0权重值所带来的问题。通过调整量化偏移和比例,可以在不改变有效表示值的情况下,将权重量化到不同的INT格式。当权重以无0的带符号INT格式表示时,通过保留额外的位,可以确保基于整数的FP-INT GEMM的计算可靠性。
基于块的尾数处理
之前的讨论假设FP激活的数据类型和FP累加器是相同的。然而,在实际场景中,在使用BF16和FP16激活时,DNN处理也常常首选FP32累加器。这样会使分配的位中可能有很大一部分未被使用,导致计算资源的未充分利用。在这种情况下,作者认为预对齐尾数的位需求应该基于累加器数据类型来计算,因为尾数截断应该模仿传统操作的舍入。
所以提出了一种基于块的尾数分配方法。块是一组二进制数字,作为表示预对齐值的基本单位。例如,使用7位块时,需要总共5个块来表示原始的34位预对齐尾数。然而,在BF16激活的情况下,只有2个连续的块包含有效值,而剩下的3个块则填充为零。为了提高效率,块分配器通过传递由包含所有有效值的2个连续块组成的14位值,以及这2个块的位置来表示预对齐尾数。由于包含有效值的块有4个可能的位置,因此这个位置信息需要额外的2位来表示。通过采用这种基于块的方法,我们可以有效地将预对齐尾数的大小从34位减少到16位,而不会丢失任何相关信息。
硬件架构
测试结果
Microscaling Data Formats for Deep Learning
基本信息
- 时间:2023年10月,arxiv
- 作者:多名
- 单位:多家大公司
主要内容
主要是评估了微缩放MX数据格式,展示实验数据,不仅是推理,也包括训练,都是合适的
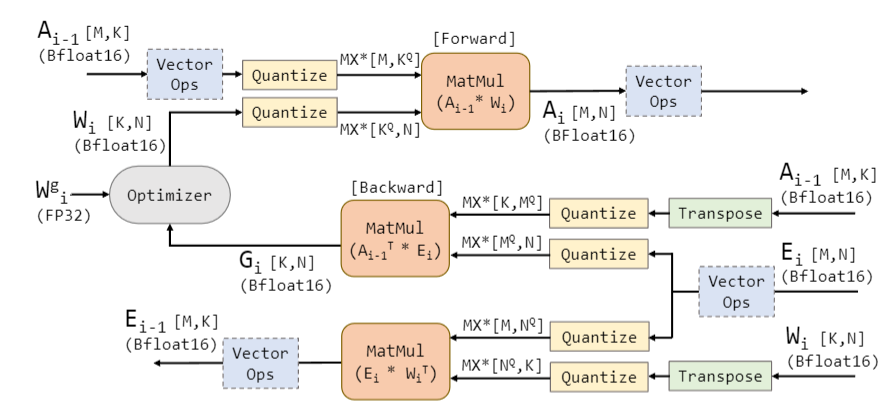
对于前向和反向传递中涉及点积的操作,两个输入被转换为MX格式,按照OCP微缩放规范高效点积来执行的。向量操作(例如,层归一化、Softmax、GELU和残差加法)是在类似Bfloat16或FP32的标量浮点格式中执行的。点积操作产生标量浮点格式的输出。保持一份权重的主副本在FP32中,并且这个副本在每个训练步骤中进行更新。
计算结果
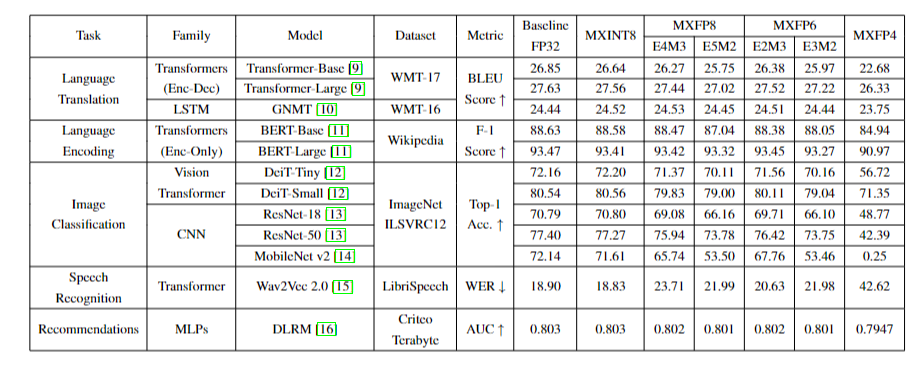
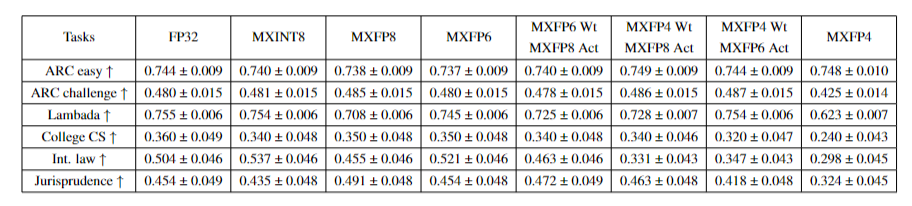
MXINT8在GPT3-175B和LLaMA-7B的所有任务上与基线FP32的精度相差在标准差范围内。对于MXFP8和MXFP6,具有更多尾数位的格式变体更适合直接转换推理。
OCP Microscaling Formats (MX) Specification
基本信息
- 时间:2023年9月
- 作者:多名
- 单位:多家大公司
内容
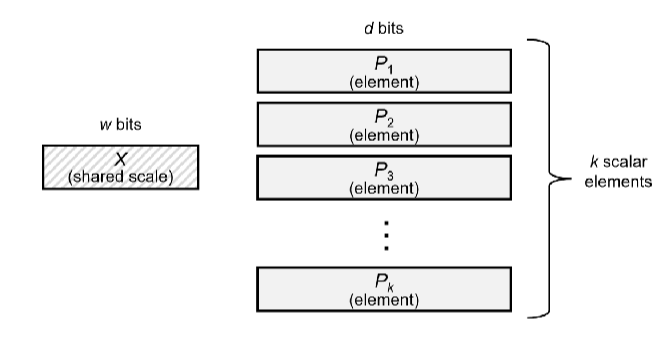
就是一个关于MX的规则陈述,对一些名词做解释以及基本的运算规则。
MX具体开源代码在:https://github.com/microsoft/microxcaling
浮点数相关概念:fp16规格数和非规格数
ReDCIM: Reconfigurable Digital ComputingIn-Memory Processor With Unified FP/INT Pipeline for Cloud AI Acceleration
基本信息
- 时间:2022年 ISSCC
- 作者:涂锋斌、谢源、尹首一等人
基本内容
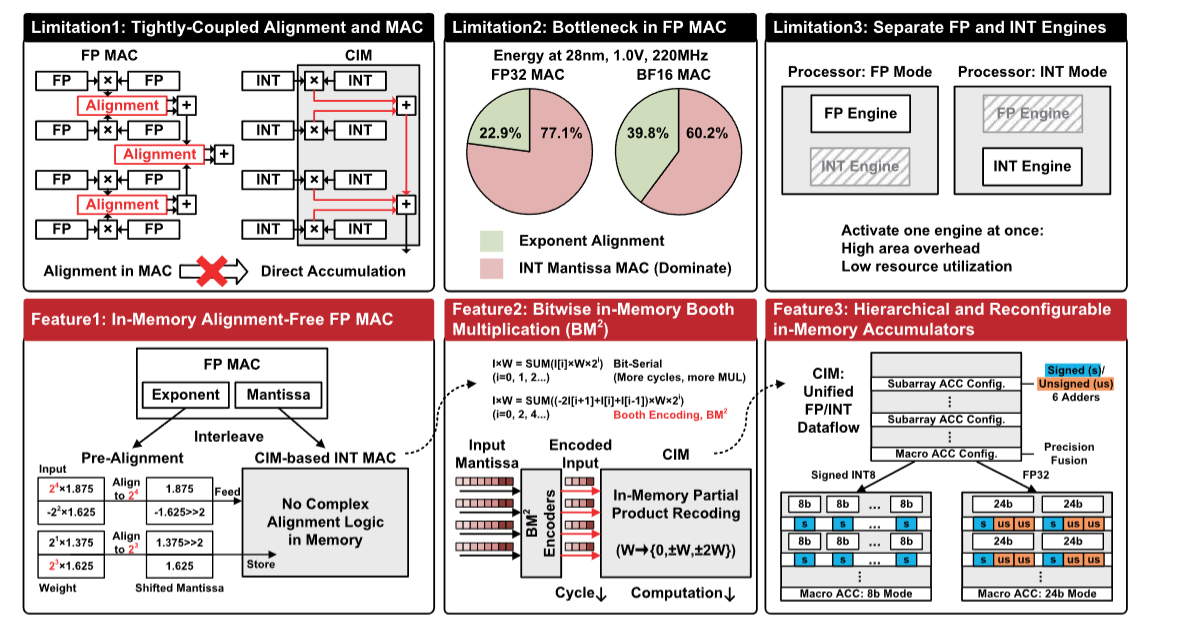
挑战1
挑战: 浮点乘累加操作中指数对齐与整数尾数MAC操作紧密耦合。在内存中实现复杂的指数对齐将损害CIM的直接累加结构并降低效率
解决方法: 在传统的浮点乘累加中,整数尾数乘累加是通过将输入和权重的Mantissa+值相乘,然后将乘积累加到部分和中。而作者同时处理一组浮点乘累加:预先将它们的输入和权重指数对齐到局部最大值$E_{Imax}$和$E_{Wmax}$。这样,在此组中,乘积的指数$(E_{Imax} + E_{Wmax} - 127)$和部分和的指数$E_{O}$始终相同,因此在整数尾数乘累加期间无需执行指数对齐。
挑战2
挑战: FP MAC的能量消耗主要来自于整数尾数MAC。基于CIM的整数MAC进一步加速对整个处理器的能效至关重要。
解决方法: 作者提出$BM^{2}$以提供对传统位串行乘法的加速。对输入$I$进行基4的Booth编码。
原先的计算方式:
$$I \times W=\sum_{i=0}^{n-1}\left(I[i] \times W \times 2^i\right)$$
后来计算方式改为:
$$I \times W=\sum_{i=0, i+=2}^n\left((-2 I[i+1]+I[i]+I[i-1]) \times W \times 2^i\right)$$
挑战3
挑战: 以前的云AI处理器通常具有独立的FP和INT引擎,但一次只激活一个引擎,导致面积开销高且资源利用率低。
解决方法: ReDCIM的FP和INT模式在同一个CIM核心中重用相同的$IAU-BM^{2}$控制器-CIM宏数据路径,由于CIM宏应该被不同的工作模式重用,作者设计了分层次和可重配置的内存中累加器,以灵活支持BF16/FP32和INT8/INT16在一个$BM^{2}-CIM$宏中。
测试结果
OPAL: Outlier-Preserved Microscaling Quantization Accelerator for Generative Large Language Models
基本信息
- 会议/期刊:DAC’24
- 作者:Jahyun Koo、Dahoon Park(通讯:Jaeha Kung)
- 单位:高丽大学
挑战
大型语言模型规模不断增大,对内存大小和带宽带来更多的负担。最近的研究了激进的权重量化,而在激活量化方面的研究则相对缺乏:
- 当权重4位量化时,需要进行激活函数量化进一步加速。
- 动态量化激活函数需要提取最小/最大值并使用除法器来考虑缩放因子,带来显著的硬件开销
贡献
- 提出了一种保持异常值的微缩放整数格式来实现基于移位的动态量化器。保留每个块中的少数异常值,即每个块中最大的四个绝对值,而将非异常值量化为3/5位或4/7位。
- 提出了一种基于对数的softmax函数近似方法。
- 提出对应的硬件加速器OPAL。
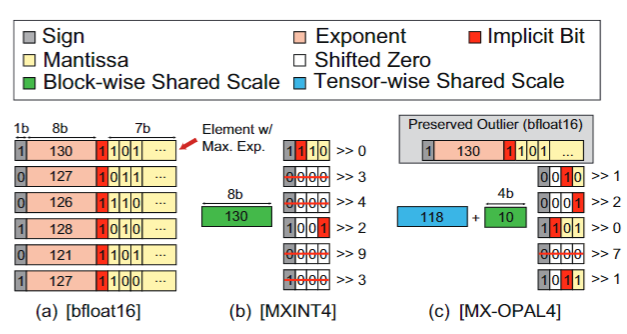
作者对激活使用MX-OPAL方法(文章所提),而对权重使用OWQ方法(引用前人工作)。MX-OPAL把大的异常值保留bfloat16格式,非异常值转换为少位MX-OPAL(图示为4位,算法中根据不同层情况选择3-4位),保留了前$𝑛$个异常值,提取第$(𝑛+1)$高的指数值作为共享比例,为整个张量设置一个全局共享比例并为每𝑘个元素存储一个4位块偏移,以最小化共享比例的数据大小。
与MXINT4相比,可以使用提出的MX-OPAL4减少下溢的数量。
新的softmax计算方法
修改log2部分如下:
$$\begin{aligned}\left\lceil\log 2\left(\frac{e^{x_i}}{\sum e^{x_i}}\right)\right\rfloor & =\left\lceil\log 2\left(e^{x_i}\right)-\log 2\left(\sum e^{x_i}\right)\right\rfloor \ & =\left\lceil\log 2\left(2^{E_i} \cdot 1 \cdot M_i\right)-\log 2\left(2^{E{\Sigma}} \cdot 1 . M{\Sigma}\right)\right\rfloor \ & =\left(E_i-E{\Sigma}\right)+\left\lceil\log 2\left(1 \cdot M_i\right)-\log 2\left(1 \cdot M{\Sigma}\right)\right\rfloor \ & =\left(E_i-E{\Sigma}\right)+\operatorname{Sign}\left(M_i-M{\Sigma}\right) \circ 1{\left|M_i-M_{\Sigma}\right| \geq 0.5},\end{aligned}$$
$𝐸_{𝑖}$ 是 $𝑒^{𝑥_{𝑖}}$ 的指数,$1.𝑀_{𝑖}$ 是 $𝑒^{𝑥_{𝑖}}$ 的尾数+1,$E_{\Sigma}$是$\sum e^{x_i}$的指数,$1 . M_{\Sigma}$是$1 . M_{\Sigma}$的尾数+1。由于 $1.𝑀$ 总是介于 1 和 2 之间,$\log _2(1 . M)$是一个介于 0 和 1 之间的值。
数据流
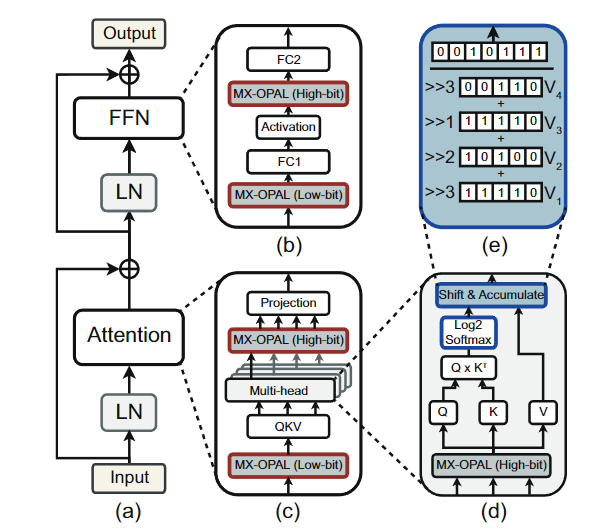
有两个主要计算层需要大量参数:一个前馈网络和一个注意力层。由于激活值通过LN行归一化,激活值的分布被限制在特定范围内。因此,可以使用更低的位宽,例如MX-OPAL3,来量化LN层后的激活值。而其他层的激活值保持较高的位宽,例如MX-OPAL5,以保持与16位激活值相似的精度水平。在注意力层中,执行多个矩阵-向量乘法($M \times V$)以计算$𝑄$、$𝐾$、$𝑉$和注意力图。
硬件架构
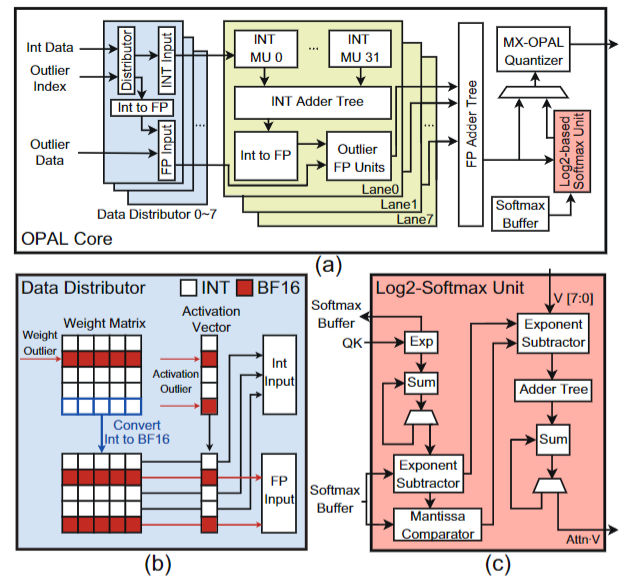
每个核心由八个数据分配器、八个MxV计算通道、一个浮点加法树、一个基于log2的softmax单元和一个MX-OPAL量化器组成。每个核心接收128个激活值作为输入,这些激活值按情况是低比特整数(3或4位)或高比特整数(5或7位),以及一个4位共享尺度,其中包括四个bfloat16异常值。位于每个计算通道前的数据分配器将非异常值路由到整数乘法单元,将异常值路由到浮点单元。由于激活值中的异常值数量多于权重,作者将权重矩阵中与激活异常值对齐的一些通道从INT3/4转换为BF16。大多数激活值和权重被导向INT MUs。
性能
算法
模型: Llama2和OPT
任务: WikiText-2、C4、ARC_Challenge和PIQA
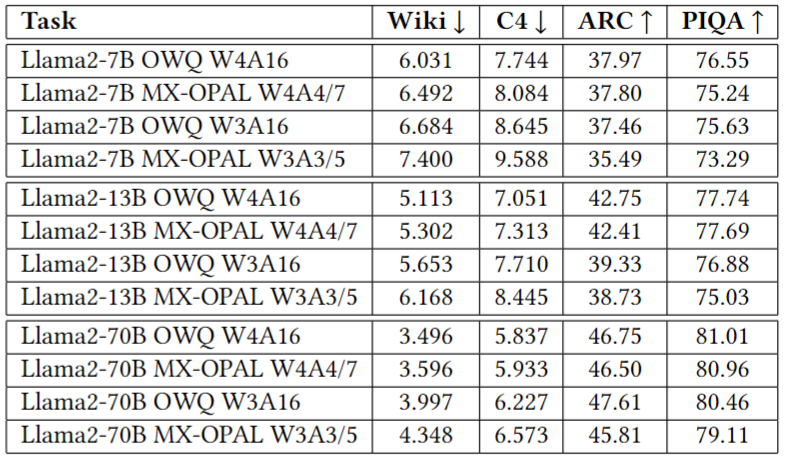
与使用BF16进行激活的OWQ进行比较,使用W4A4/7时,MX-OPAL在Wiki和C4上的PPL仅增加了0.241,在ARC和PIQA上的准确性平均下降了0.36%。在更激进的量化,即W3A3/5下,MX-OPAL在Wiki和C4上的PPL增加了0.601,在ARC和PIQA上的准确性平均下降了1.65%。
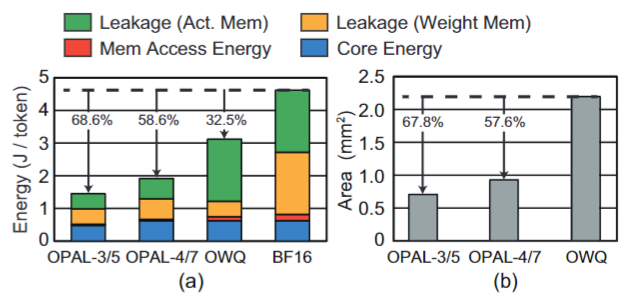
硬件
使用Synopsys DC根据65nm CMOS技术来估计功耗和面积。使用CACTI估计能量消耗。对于Llama2-70B,在OPAL上生成一个令牌的延迟为1.98秒,与OWQ/BF16相比,平均节省53.5%/68.6%的能量消耗(对于W3A3/5)和38.6%/58.6%的能量消耗(对于W4A4/7)。