
Transformer非线性单元的硬件优化方案
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
有关Quest和H2O的对比:
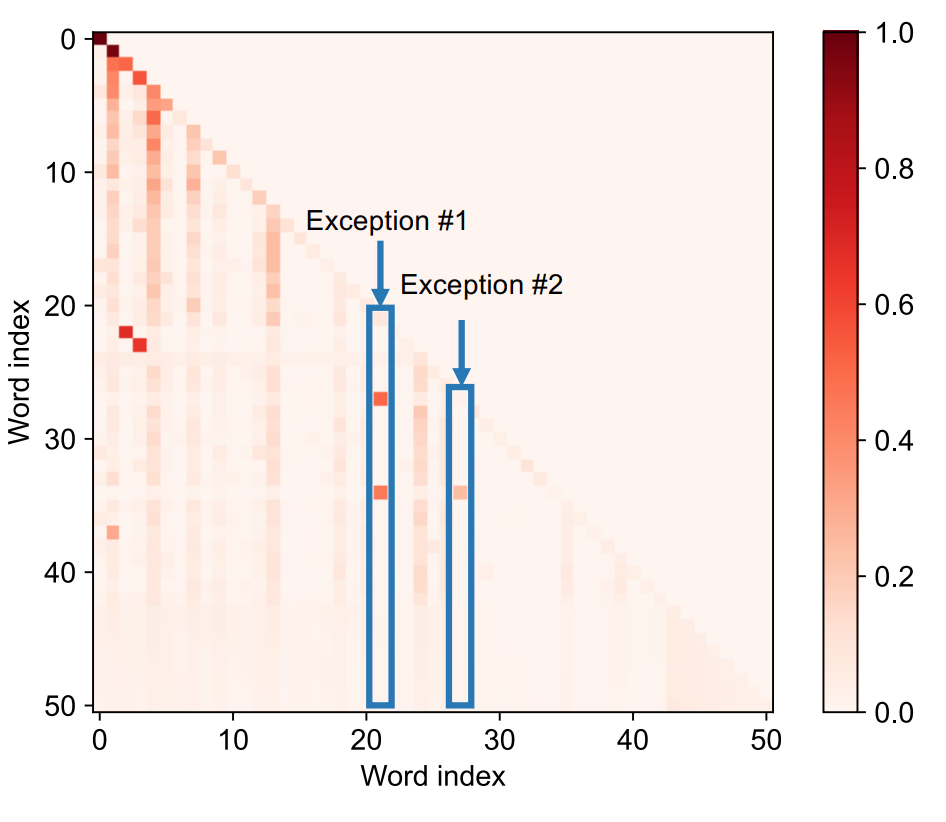
主要区别
H2O采取的是贪心算法,每次剔除掉的token是永久性的,也就是下次不会再有被删除的token,就会影响模型性能。而Quest提出一种非永久剔除Token的动态构建Token候选集算法:
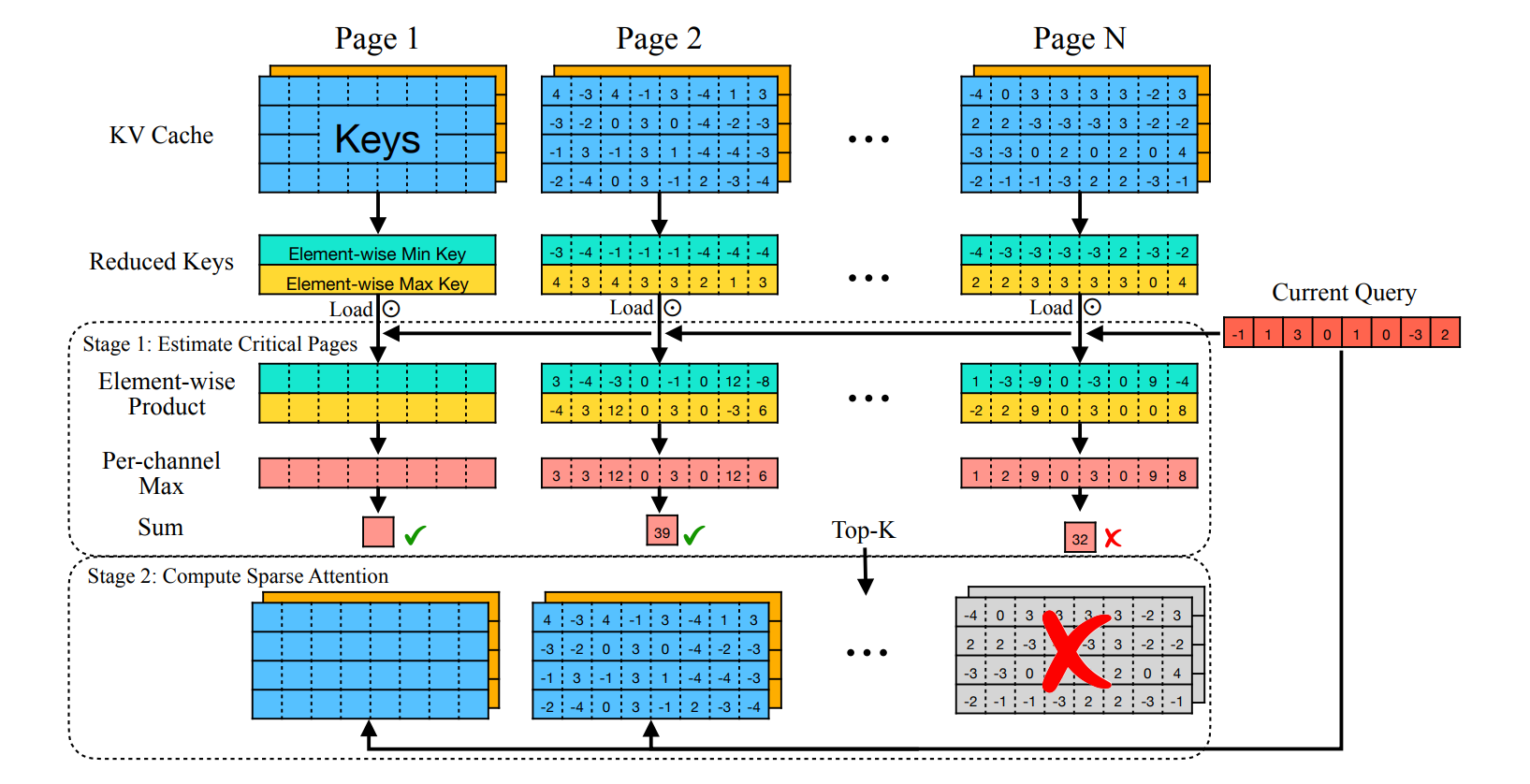
Quest保留所有之前的Token,每轮都会计算当前的Token和过去所有Token的相关性,然后用TopK的算法选取相关性最高的K个Token参与Attention计算。这样计算会导致计算负载又增加,因此具体而言,Quest是选Page(Quest用Page Attention技术对KVCache进行管理)而非Token。
之后论文介绍了如何计算一个Page的相关性得分:Quest在常规的KVCache页表基础上,新增了一个MetaKVCache页表,用于存储每个KVCache页最大和最小的Key向量。Query向量分别和最大最小Key向量进行Elementwise乘法,得到两个向量结果。对两个向量结果进行Elementwise Max,得到一个向量结果,再求和,得到该Page的得分;根据得分选择Top K个Page作为Token候选集。
经过计算后,保存这次的mask:
1 | # 克隆注意力掩码,并增加两个维度以匹配后续操作的期望形状 |
然后下次计算带回之前的mask:
1 | # 如果存在下一个注意力掩码,则更新注意力权重 |
Hardware-Efficient SoftMax Architecture With Bit-Wise Exponentiation and Reciprocal Calculation
这篇论文介绍的是SoftMax计算的整体架构优化。对于指数运算,保持以e为底,并以流水线的方式执行位运算。对于除法,通过计算总指数和的倒数值来使用除法通过乘法的方法。然后将倒数值乘以单个指数值以获得最终的SoftMax值。为了确保数值稳定性,选择减去$\widehat{x_{\max }}$,它比$x_{max}$在表示上更为简单。
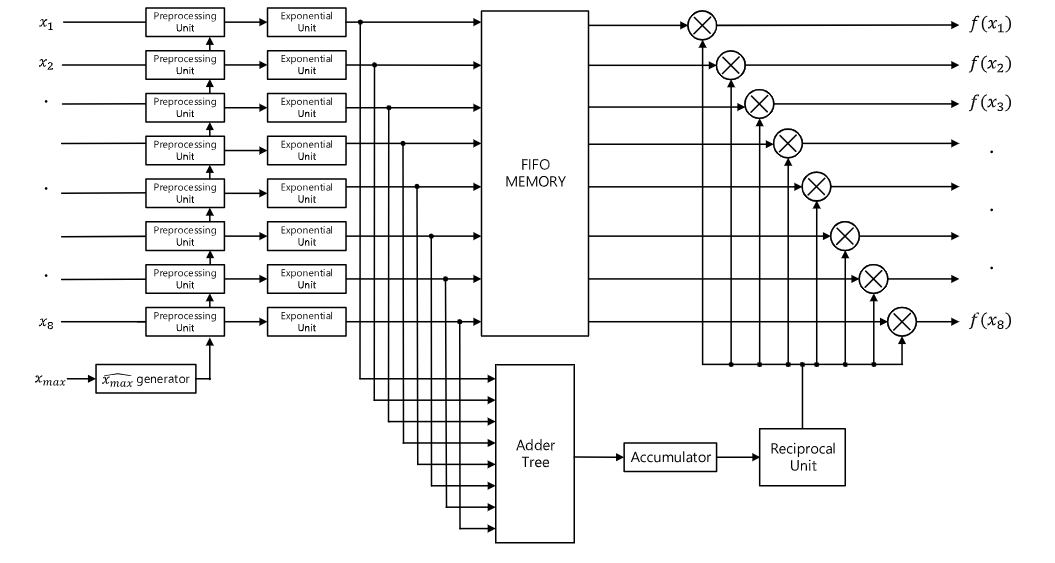
预处理单元
为了实现数值稳定性,所提出的方法采用了一种方法,即从每个输入值中减去 $\hat{x_{max}}$ 的估计值。如果 $x_{max}$ 是正数,那么$\hat{x_{max}}$的估计值取$x_{max}$的整数部分,即截断小数部分。如果$x_{max}$是负数,那么$\hat{x_{max}}$的估计值设为0。
指数单元
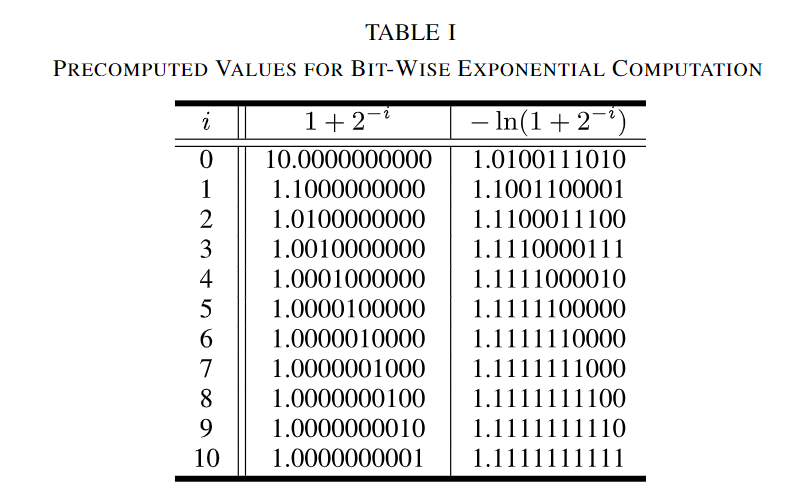
指数单元变换成如下形式,增加一些常数减少计算量,$I$和$F$对应$w \cdot \log _2 e$的整数部分和小数部分,一部分转为2的移位操作,另一部分通过查找表简化计算。
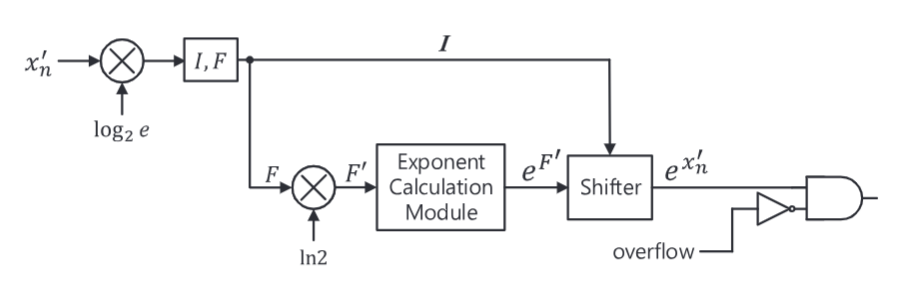
$$e^w=e^{w \cdot \log _2 e \cdot \ln 2}=e^{(I+F) \cdot \ln 2}=2^I \cdot e^{F \cdot \ln 2}$$
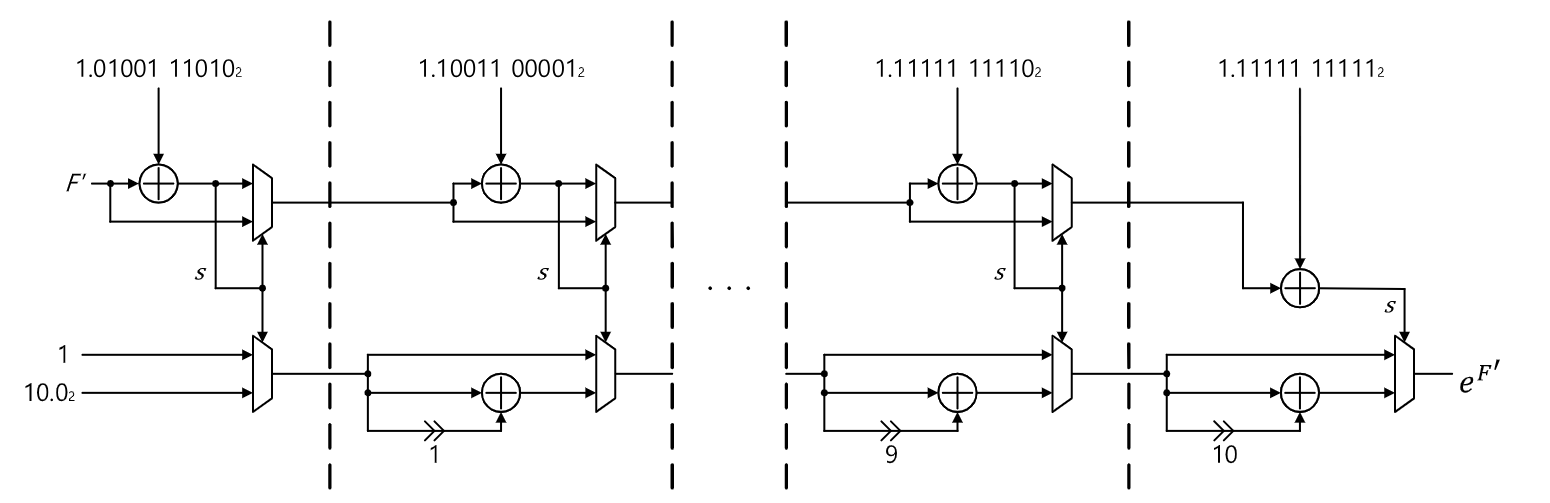
$e^{F \cdot \ln 2}$的计算则是依靠查找表进行,将其分解为多个$e^{w} = 1 + 2^{i}$相乘,具体到硬件则是计算好每个$i$再根据设定的计算模式计算:
$$
e^w=e^{\sum_{i=0}^n w_i}=e^{w_0} e^{w_1} \cdots e^{w_n}=\prod_{i=0}^n b_i
$$
倒数单元
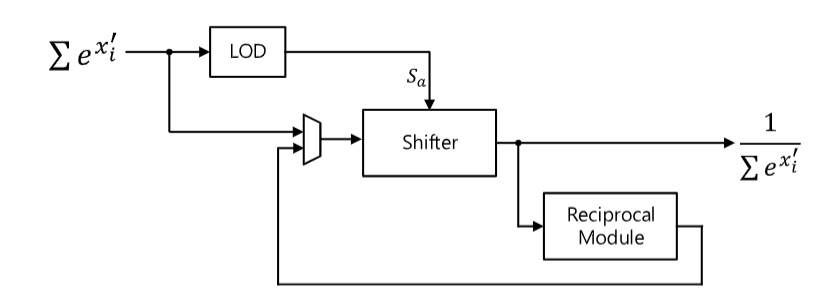
计算倒数值主要有两种方法:收敛法和被称为牛顿-拉夫森法的倒数法,本文使用收敛法:
$$
\begin{aligned}
\frac{1}{Q} & =\frac{R_0 R_1 \cdots R_{n-1}}{Q \cdot R_0 \cdot R_1 \cdots R_{n-1}}=\frac{\prod_{i=0}^{n-1} R_i}{D_n} \cong \prod_{i=0}^{n-1} R_i \
D_n & = \begin{cases}Q & (n=0) \
D_{n-1} \cdot R_{n-1} & (n \geq 1)\end{cases}
\end{aligned}
$$
$Q$位于0和1之间,$R_i=1+r^{2^i}$。$r$在$(0, 1)$,$D_1=D_0 \cdot R_0=(1-r)(1+r)=1-r^2$,如公式(8)所示。同样,$D_n=D_{n-1} \cdot R_{n-1}$。重复这个过程$n$次,分母变为$D_n=1-r^{2^n}$,随着n的增加,它收敛到1。同时,分子收敛到Q的倒数。给定$D_i=1-k$,可以使用$R_i=1+k=2-D_i$计算$R_{i}$,通过取$D_{i}$的2的补码可以得到$R_{i}$。
输入的指数值和是20位的值表示,由一个10位的整数和一个10位的小数组成。为了使总的指数和位于(0, 1)的范围内,总的和通过一个移位量Sa向右移位。移位量是通过检测总和中最高位1的位置来确定的。最高位检测器是LOD,检测整数部分中最高位1的位置。如果最高位1的位置是P,那么Sa = P + 1。
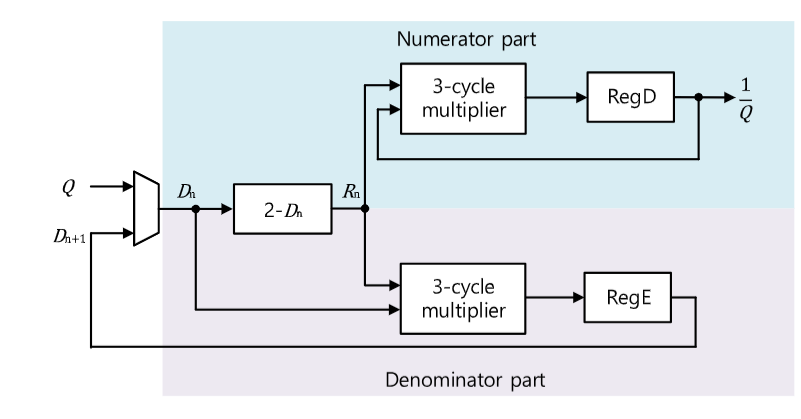
对于8位输入是4次迭代,对于16位输入是5次迭代。
TF-MVP: Novel Sparsity-Aware Transformer Accelerator with Mixed-Length Vector Pruning
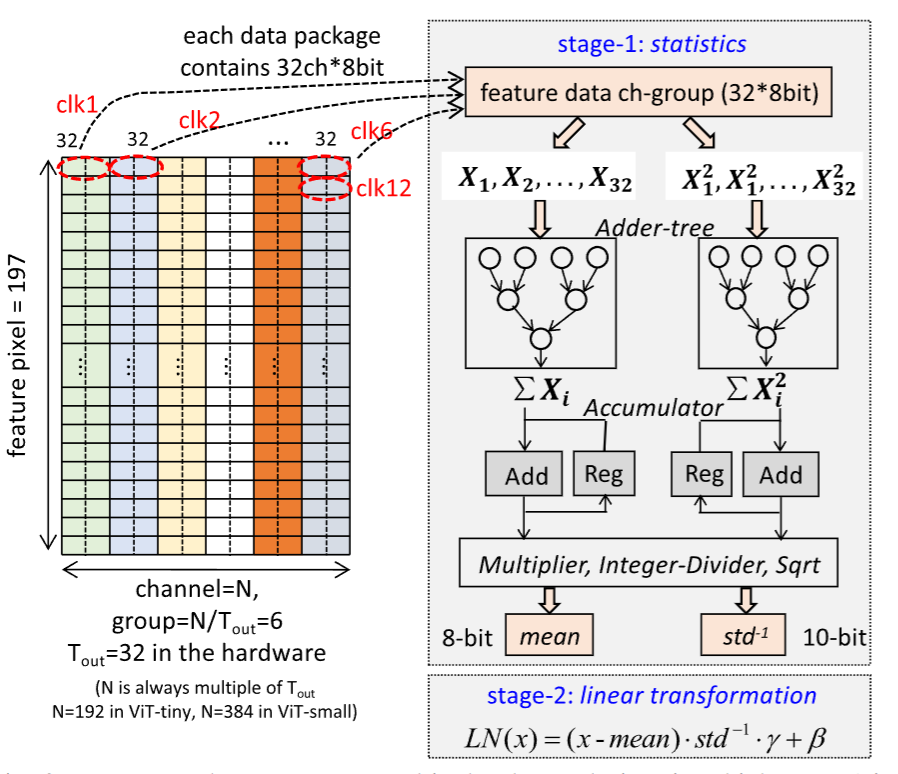
LN的硬件优化
LN的公式:
$$L N(x)=\frac{x-\operatorname{Mean}(x)}{\sqrt{\operatorname{Var}(x)+\varepsilon}} \cdot \gamma+\beta$$
论文主要是对方差部分进行优化:
$$
\operatorname{Var}(x)=E{[x-E(x)]^2}=E(x^2)-[E(x)]^2
$$
按照数学公式可以把方差变成两个期望值相减,因此做到只进行一次数据访问以及并行计算(文章提到,原先需要两次数据访问,第一次用于计算均值,第二次用于计算(x-均值)的差)。
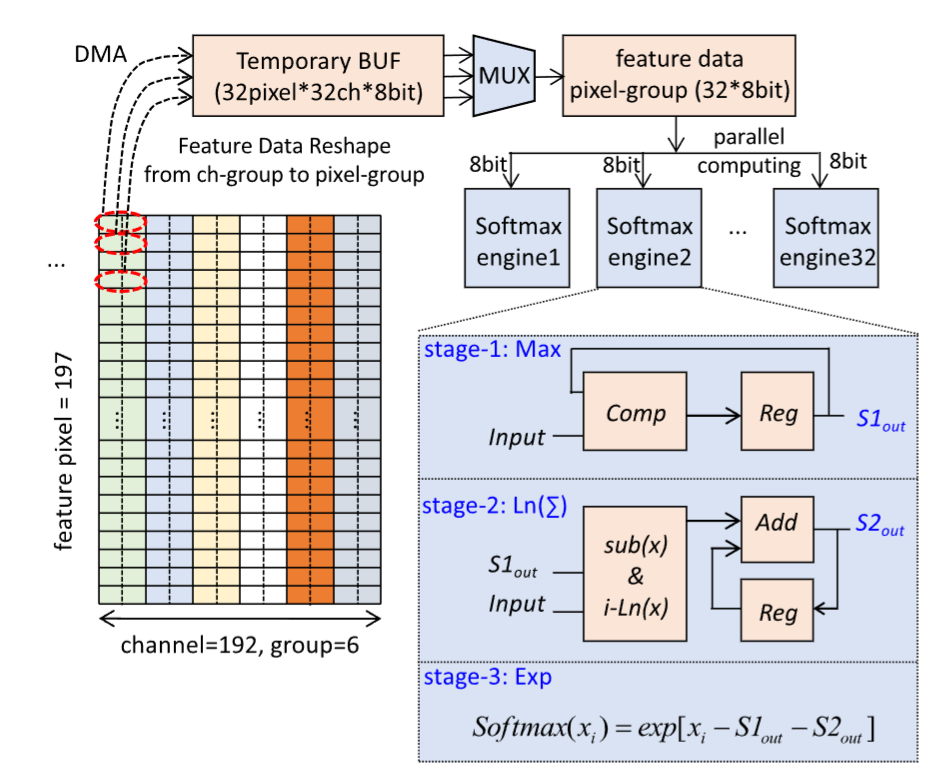
SoftMax的硬件优化
借鉴的方案里提出的是ShiftMax,有一定的硬件友好性,但是作者认为它仍然需要大量的除法操作,所以进一步改进。关键思想是通过减去最大值来缩放参数,然后使用指数函数的底数变换公式进行等效变换:
$$
\operatorname{Softmax}\left(x_i\right)=\exp \left{x_i-X_{\max }-\ln \left[\sum_j^N \exp \left(x_{\mathrm{j}}-X_{\max }\right)\right]\right}
$$
$$
\begin{aligned}
\exp (x) & =2^{\left[\left(\log _2^{\mathrm{e}}\right) \cdot x\right]}=2^{u+v} \approx 2^u \cdot(1+0.5 v) \
\ln (x) & =\ln 2 \cdot \log _2 x=\ln 2 \cdot\left(\mathrm{w}+\log _2 k\right) \
& \approx \ln 2 \cdot(w+k-1)
\end{aligned}
$$
其中,
$$
\left{\begin{array}{l}
u=\left\lceil\left(\log _2^{\mathrm{e}}\right) \cdot x\right\rceil \
v=\left(\log _2^{\mathrm{e}}\right) \cdot x-u \
k \cdot 2^w=x \
k \in[1,2)
\end{array}\right.
$$
GELU激活的硬件优化
$$
\operatorname{Gelu}(x)=x \cdot \frac{1}{\sqrt{2 \pi}} \int_{-\infty}^x e^{-t^2 / 2} d t \approx x \cdot \frac{1}{2}\left[1+L\left(\frac{x}{\sqrt{2}}\right)\right]
$$
$L(x)$函数如下:
$$
L(x)=\operatorname{sgn}(x)\left[\alpha(\operatorname{clip}(|x|, \max =-\beta)+\beta)^2+1\right]
$$
其中$\alpha = -0.2888$,$\beta = -1.769$。
I-LLM: Efficient Integer-Only Inference for Fully-Quantized Low-Bit Large Language Models
算法过程
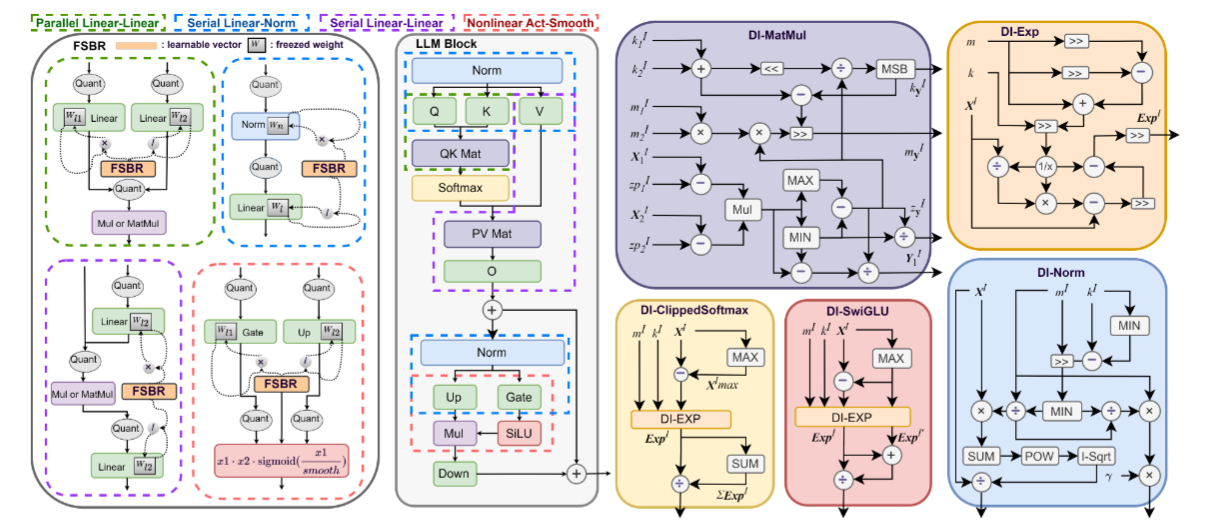
论文核心是动态量化部分,根据计算的结果选取合适的scale。作者定义矩阵乘法如下:
$$
\boldsymbol{Y}^{\boldsymbol{I}}, m_y^I, k_y^I, z p^I=\mathcal{M}\left(m_1^I, k_1^I, z p_1^I, \boldsymbol{X}_1^{\boldsymbol{I}}, m_2^I, k_2^I, z p_2^I, \boldsymbol{X}_2^{\boldsymbol{I}}\right)
$$
其中,$s = \frac{m^I}{2^{k^I}}$,$m^{I}$和$k^{I}$为8位整数,$zp_{1}^{I}$为对应的零点。进行两个矩阵的量化后计算出一个中间结果和对应的浮点结果:
$$
\boldsymbol{P}^{\boldsymbol{I}}=\left(\boldsymbol{X}_1^I-z p_1^I\right)\left(\boldsymbol{X}_2^I-z p_2^I\right), \quad \boldsymbol{Y}=\boldsymbol{P}^{\boldsymbol{I}} \frac{m_1^I m_2^I}{2^{k_1^I+k_2^I}}
$$
获得输出的量化scale:
$$
\frac{m_y^I}{2^{k_y^I}} \approx s_y=\frac{\left(p_{\max }^I-p_{\min }^I\right) \cdot m_1^I \cdot m_2^I}{\left(2^{n^I}-1\right) \cdot 2^{k_1^I+k_2^I}}
$$
多次迭代后找到合适的量化参数,论文设置$m_{y}^{I} = 256$然后来搜索合适的$k_{y}^{I}$:
$$
\underset{m_y^I, k_y^I}{\arg \min }\left|\frac{\left(p_{\max }^I-p_{\min }^I\right) \cdot m_1^I \cdot m_2^I}{\left(2^{n^I}-1\right) \cdot 2^{k_1^I+k_2^I}}-\frac{m_y^I}{2^{k_y^I}}\right|_1 \quad \text { s.t. } \quad m_y^I, k_y^I \in 0,1,2, \ldots, 255
$$
利用位移操作来实现指数函数和除法操作,这些操作是动态量化所必需的。例如,使用位移操作来近似指数函数:
$$
\begin{gathered}
k_y^I=\left\lfloor\log 2\left(\frac{256 \cdot\left(2^{n^I}-1\right) \cdot 2^{k_1^I+k_2^I}}{p{\max }^I-p_{\min }^I}\right)\right\rfloor=\left\lfloor\log 2\left(\frac{\left(2^{n^I}-1\right) \cdot 2^{k_1^I+k_2^I+8}}{p{\max }^I-p_{\min }^I}\right)\right\rfloor \
m_y^I=\left\lfloor\frac{\left(p_{\max }^I-p_{\min }^I\right) \cdot m_{x 1}^I \cdot m_{x 2}^I}{n^I} \gg\left(k_1^I+k_2^I-k_y^I\right)\right\rfloor \
z_y^I=\left\lfloor\frac{-p_{\min }^I \cdot\left(2^{n^I}-1\right)}{p_{\max }^I-p_{\min }^I}\right\rfloor, \quad Y^I=\left\lfloor\frac{\left(P^I-p_{\min }^I\right) \cdot\left(2^{n^I}-1\right)}{p_{\max }^I-p_{\min }^I}\right\rfloor
\end{gathered}
$$
DI-MatMul只使用整数运算,仅引入了一些额外的整数标量计算,使其比之前的方法更高效。能够主动识别并适应输入数据的多样性,从而减少量化误差,提高整体模型性能。
DI-SoftMax
论文认为观察到的指数函数在-20处的值可以认为是零,对于每个令牌,只有$(x_{max} - 20, x_{max})$范围内的值对结果有贡献。对于单个令牌,通过限制$p^{I}_{min}$来约束量化范围:
$$
p_{\text {min }}^I=\max \left(p_{\text {min }}^I, p_{\text {max }}^I-c^I\right)
$$
其中,$c^I=m_c^I \cdot 2^{k_1^I+k_2^I-k_c^I}$。因此,无论动态范围如何,量化范围长度永远不会超过$c$。论文选取$c = 15$,$c=\frac{m_C^I}{2^{k_C^I}}$。
DI-Exp
$$
\mathrm{e}^{\boldsymbol{x}^I \cdot\left(m_x^I \gg k_x^I\right)}=2^{x^I \cdot\left(m_x^I \gg k_x^I\right) \cdot \log _2 e}=2^{\boldsymbol{x}^I \cdot m_x^I \cdot\left(\log _2 e \gg k_x^I\right)}
$$
其中,$s=\frac{\log _2 e}{2^{k_x^I}}$,$s^I=\left\lfloor\frac{2^{k_x^I}}{\log _2 e}\right\rceil$,则$\mathrm{e}^{\boldsymbol{x}^I \cdot\left(m_x^I \gg k_x^I\right)} \approx 2^{\left(\left\lfloor\frac{x^I}{s^I}\right\rfloor+\left(\boldsymbol{x}^I % s^I\right) s\right)} \approx 2^{-q^I+r^I \cdot s}$,其中$q^I=-\left\lfloor\frac{x^I}{s^I}\right\rfloor, \quad r^I=x^I % s^I$,因为$r^I \cdot s \in(-1,0]$,可以在该区间内简单地执行线性插值得到$2^{r^I \cdot s} \approx 1-\frac{r^I}{2 \cdot s^I}$:
$$
\mathrm{e}^{\boldsymbol{x}^I \cdot\left(m_x^I \gg k_x^I\right)} \approx\left(1-\frac{r^I}{2 \cdot s^I}\right) \gg q^I
$$

DI-Norm
对LayerNorm和RMSNorm的输入进行逐通道量化。直接计算均值,计算方差使用位检查方法来实现更高的精度。

DI-SwiGLU
在块重建阶段,将SwiGLU的SiLU激活函数分解为$\operatorname{SiLU}(x)=x \cdot \sigma(x)$,以实现非线性平滑。主要就是DI-Exp的多次调用。

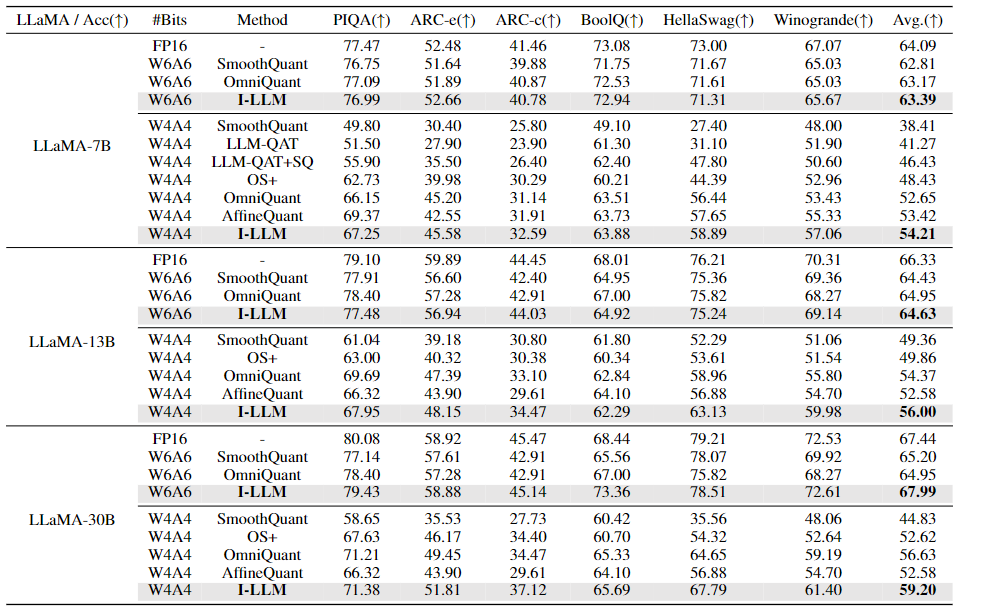
性能
模型: 包括OPT,LLaMA,LLaMA2、LLaMA3-8B
数据集: WikiText2和C4上测试量化对困惑度的影响。零样本任务中评估准确性,包括PIQA,ARC,BoolQ,HellaSwag,Winogrande
An Efficient FPGA-Based Accelerator for Swin Transformer
GELU部分
$$
g\left(x_i\right)=0.5 x_i\left(1+\tanh \left(\sqrt{\frac{2}{\pi}}\left(x_i+0.044715 x_i^3\right)\right)\right)
$$
转化为:
$$
\begin{aligned}
& g\left(x_i\right)=0.5 x_i\left(1+\frac{e^{h\left(x_i\right)}-e^{-h\left(x_i\right)}}{e^{h\left(x_i\right)}+e^{-h\left(x_i\right)}}\right) \
& =\frac{x_i e^{h\left(x_i\right)}}{e^{h\left(x_i\right)}+e^{-h\left(x_i\right)}}=\frac{x_i}{1+2^{-2 \log _2 e \cdot h\left(x_i\right)}}
\end{aligned}
$$
其中,$h\left(x_i\right)=\sqrt{\frac{2}{\pi}}\left(x_i+0.044715 x_i^3\right)$,$2^{-2 \log _2 e \cdot h\left(x_i\right)}$的指数部分则用$-2 \log _2 e \cdot \sqrt{\frac{2}{\pi}}\left(x_i+0.044715 x_i^3\right)$表示。
$\log _2 e$用二进制近似表示为:1.0111。表示为1 + 0.1 - 0.0001。由此使用两次移位操作和两次加减操作来计算$\log _2 e \times x_i$。
$−2 \log_2 e · q / (2π)$可以用二进制近似表示为:-10.0101 = -10 - 0.01 - 0.0001。0.044715可以用二进制近似表示为:0.000011 = 0.000001 + 0.00001。
SoftMax部分
$$
f\left(x_i\right)=\frac{2^{\log 2 e\left(x_i-x{\max }\right)}}{\sum_{j=1}^n 2^{\log 2 e\left(x_j-x{\max }\right)}}
$$
SoftMax先转化为以2为底的幂函数:
$$\begin{aligned} 2^{\log _2 e \cdot x_i} & =2^{v\left(x_i\right)}=2^{\operatorname{int}\left(x_i\right)} \cdot 2^{\operatorname{frac}\left(x_i\right)} \ & =2^{\text {frac }\left(x_i\right)} \ll \operatorname{int}\left(x_i\right)\end{aligned}$$
然后对$2^{\log 2 e \cdot x_i}$集中做处理,$\log 2 e \cdot x_i$化解为整数和小数,整数为移位,小数部分分段线性近似。使用$frac(x{i})$的第9位、第8位和第7位作为标志,根据存储在查找表中的$K{i}$和$B_{j}$的值,执行分段线性近似来计算$2^{frac(x_{i})}$。
PEANO-ViT: Power-Efficient Approximations of Non-Linearities in Vision Transformers
LayerNorm部分
Layernorm部分主要是对方差的根号除法部分的整体优化:
$$
\frac{1}{\sqrt{X}}=2^{\log _2 \frac{1}{\sqrt{X}}}, \quad \log _2 \frac{1}{\sqrt{X}}=\frac{-1}{2} \log _2 X
$$
$$
\begin{gathered}
X=\sum_{i=0}^{n-1} 2^i b_i=2^{k_x}+\sum_{i=0}^{k_x-1} 2^i b_i=2^{k_x}(1+x) \
\log _2 X \approx k_x+x
\end{gathered}
$$
$k_x$是$X$的第一个1bit的位置,$x \in[0,1)$:
$$
\begin{gathered}
2^{\frac{-\left(k_x+x\right)}{2}}=2^u \cdot 2^v \
\frac{1}{\sqrt{X}} \approx 2^{\tilde{v}}<<u
\end{gathered}
$$
SoftMax的exp近似
使用帕德近似处理SoftMax的exp:
$$
\operatorname{PEANOexp}(\tilde{x})= \begin{cases}0 & \text { if } \tilde{x}<-3 \ \frac{12+6 \tilde{x}+\tilde{x}^2}{12-6 \tilde{x}+\tilde{x}^2} & \text { if } \tilde{x} \geq-3\end{cases}
$$
GELU近似
使用多项式分段处理GELU:
$$
\text { PEANO-GELU }(x)= \begin{cases}0 & \text { if } x<-3 \ -0.0414(x+3) & \text { if }-3 \leq x<-2.1 \ -0.0982(x+2.1)-0.0373 & \text { if }-2.1 \leq x<-0.75 \ 0.2266(x+0.75)-0.17 & \text { if }-0.75 \leq x<0 \ 0.6914 x & \text { if } 0 \leq x<0.5 \ 1.0617(x-0.5)+0.3457 & \text { if } 0.5 \leq x<3 \ x & \text { if } x \geq 3\end{cases}
$$
总结
非线性模块主要的方法包含:
- 统筹一个多项式替代
- 分段小函数替代
- 查找表替代计算
- Exp转为2的左移右移计算
- 基于自身量化方法做专属优化(如I-LLM)
其他近似方法补充
GELU的泰勒级数展开与帕德近似
$$
\operatorname{Gelu}(x)=x \cdot \frac{1}{2\sqrt{2 \pi}} \operatorname{erf}(x)
$$
泰勒展开:
$$
\begin{aligned}
\operatorname{erf} z & =\frac{2}{\sqrt{\pi}} \sum_{n=0}^{\infty} \frac{(-1)^n z^{2 n+1}}{n!(2 n+1)} \
& =\frac{2}{\sqrt{\pi}}\left(z-\frac{z^3}{3}+\frac{z^5}{10}-\frac{z^7}{42}+\frac{z^9}{216}-\cdots\right)
\end{aligned}
$$
帕德近似:
$$\operatorname{erf}(x) \approx \frac{2}{15 \sqrt{\pi}} \cdot \frac{49140 x+3570 x^3+739 x^5}{165 x^4+1330 x^2+3276}$$
全局帕德近似:
$$
\operatorname{erf} x \approx \operatorname{sgn} x \cdot \sqrt{1-\exp \left(-x^2 \frac{\frac{4}{\pi}+a x^2}{1+a x^2}\right)}
$$
SoftMax的帕德近似
$$
e^x \approx \frac{1+(1 / 9) * x^2+(1 / 2) * x+(1 / 72) * x^3+(1 / 1008) * x^4+(1 / 30240) * x^5}{1+(1 / 9) * x^2-(1 / 2) * x-(1 / 72) * x^3+(1 / 1008) * x^4-(1 / 30240) * x^5}
$$
LayerNorm的方差优化
$$
\operatorname{Var}(x)=E{[x-E(x)]^2}=E(x^2)-[E(x)]^2
$$




